Procedural Worlds
Description
As part of my thread optimization project, I implemented asynchronous world generation in Unreal Engine using C++. The task was offloaded to background worker threads, enabling the creation of a chunk-based world refined by Perlin noise and curve adjustments. The system supports infinite runtime expansion, allowing the world to dynamically grow as needed.
What Was Offloaded and Why
The most complex task, as could also be seen through debugging in Unreal Insights, was the calculation of vertices and triangles, as well as other data that had to be calculated for chunk generation. Accordingly, it makes sense to outsource these calculations to background workers so that they run in parallel and do not block the game thread, causing lag spikes. Due to the chunk-based structure of the terrain, it makes sense to use the chunks as subdivisions on different threads. However, the mesh must be created with the calculated values on the game thread, which is why the values must be fed back.
Why AsyncTask
To offload tasks efficiently, I utilized Unreal Engine’s Async Task system, which provides a background worker pool and handles thread management automatically. One major advantage is its integration with Unreal Insights, making debugging straightforward and implementation seamless. In his Unreal Fest talk “How to Benefit from Multithreading in Your Unreal Engine Projects” Alex Stevens highlights the many benefits of this task system. Especially in light of Unreal’s future roadmap and its evolving integration with the Task Graph system.
Why UBlueprintAsyncActionBase does not work
I have tried several systems offered by the engine, including UBlueprintAsyncActionBase, which enabled latent code execution but did not outsource execution to background workers and thus still blocked the game thread.
Test setup
- Manual test
- The duration of creating the initial area is tested
- Both actors are in the same empty level
- Both variants performed a test run before recording
- An Unreal Insights trace is started for test accuracy and visualization
- Same settings
| Setting | Value |
|---|---|
| Chunk Size | 2500cm |
| Chunk Segments | 25 |
| Chunk Range | 5 |
Computer Specifications
| Component | Name |
|---|---|
| CPU | AMD Ryzen 7 5800X 8-Core Processor |
| GPU | NVIDIA Gigabyte GeForce RTX 3060 OC |
| RAM | 32 GB DDR4 |
| Mainboard | Gigabyte X570S UD F2 |
| Hard drive | NVMe Samsung SSD 980 Pro 1TB |
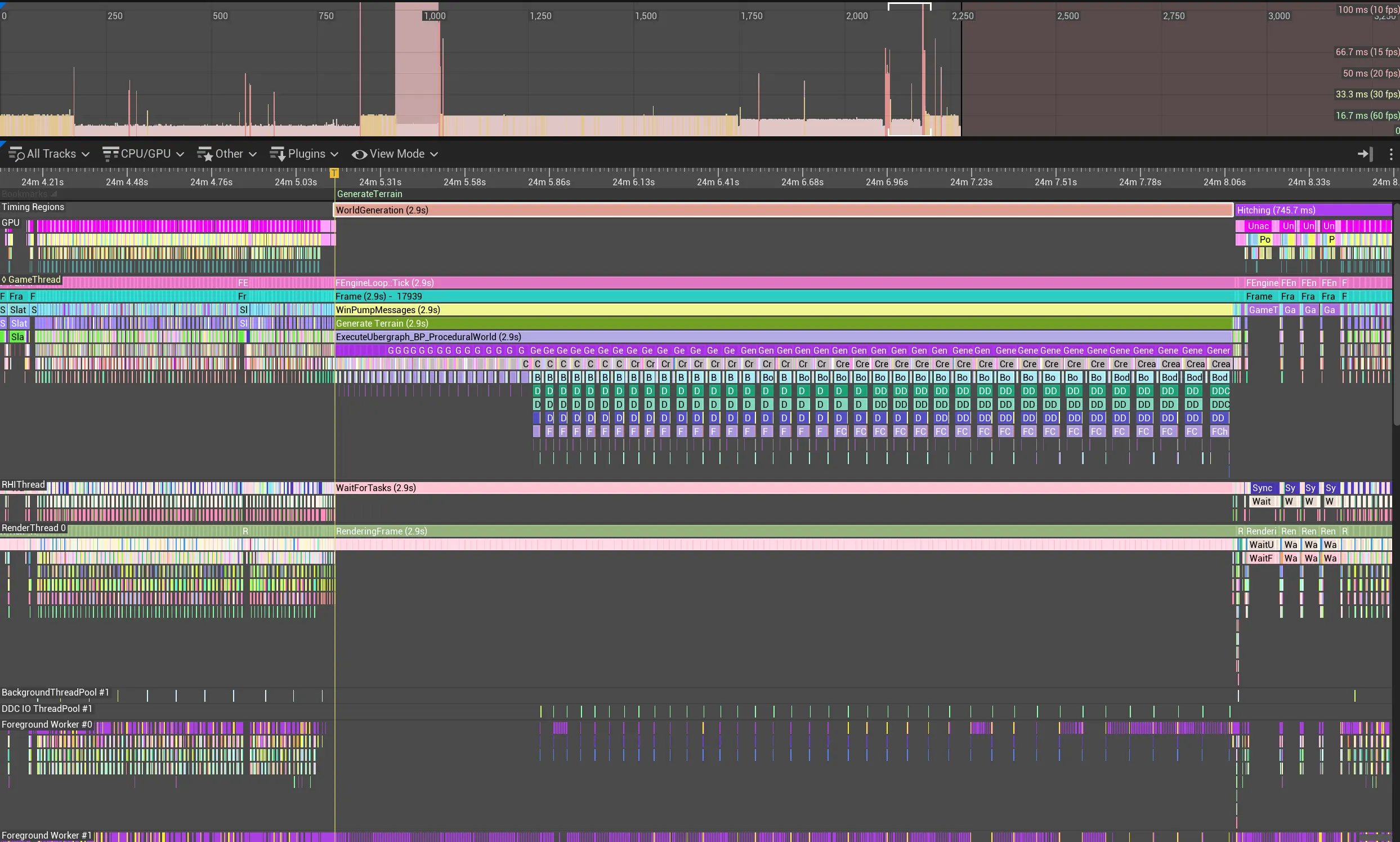
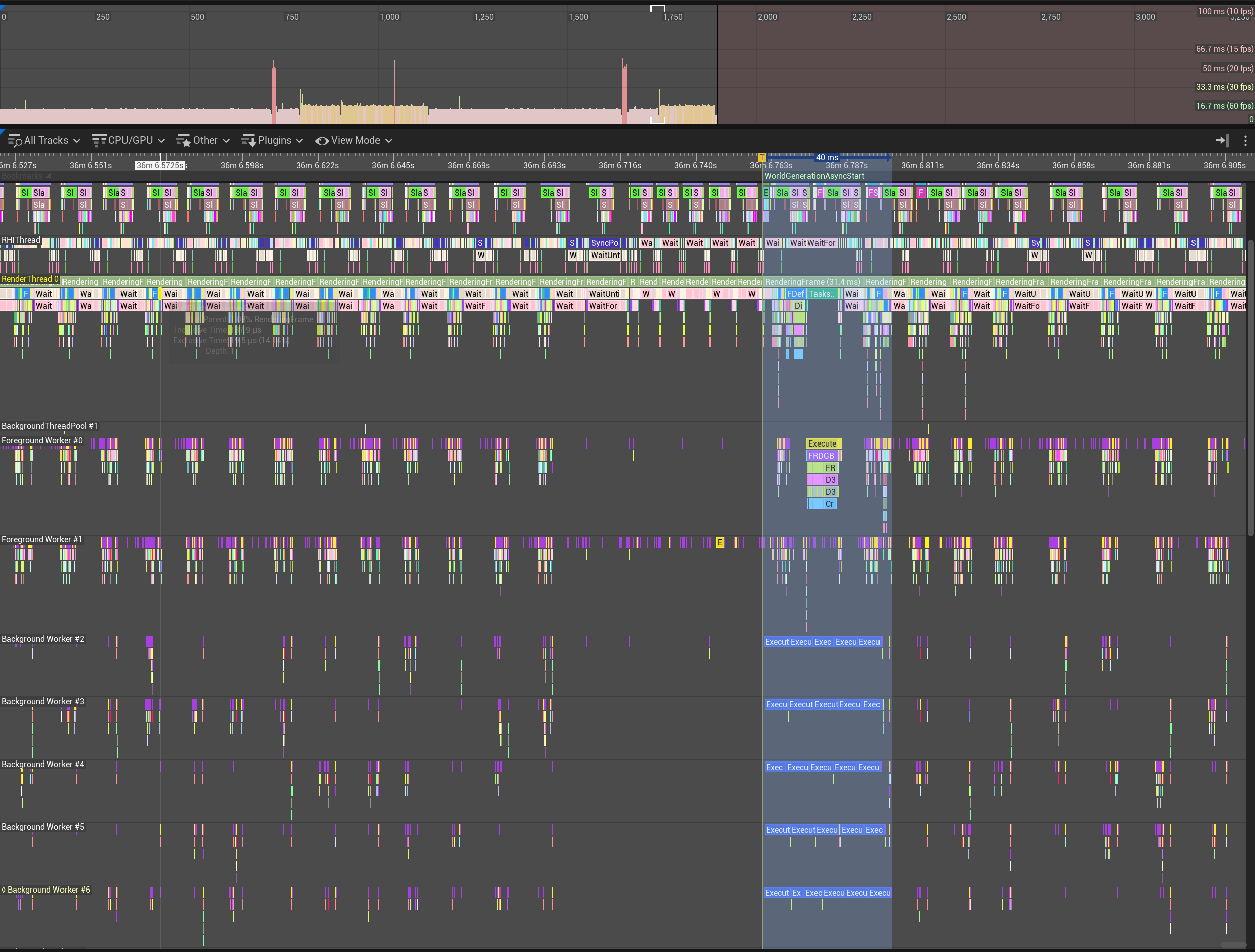
Tracked Performance Data
Before
After
Comparison
| Test Run | Without Multithreading | With Multithreading |
|---|---|---|
| 1. | 3000,0ms | 40,0ms |
| 2. | 2900,0ms | 40,5ms |
| 3. | 2900,0ms | 39,0ms |
| 4. | 2900,0ms | 38,4ms |
| 5. | 2900,0ms | 39,7ms |
| ~ 2900,0ms | ~ 39,5ms |
Evaluation
Before optimization, the execution of the non-multithreaded code took 2900,0 ms, and after optimization, only 39,5 ms. Dividing 2900,0 ms by 39,5 ms yields a value of ~73.3805. It can therefore be said that the optimization was very successful, as a performance increase of more than 73 times was recorded.
Gallery


